
Abstract
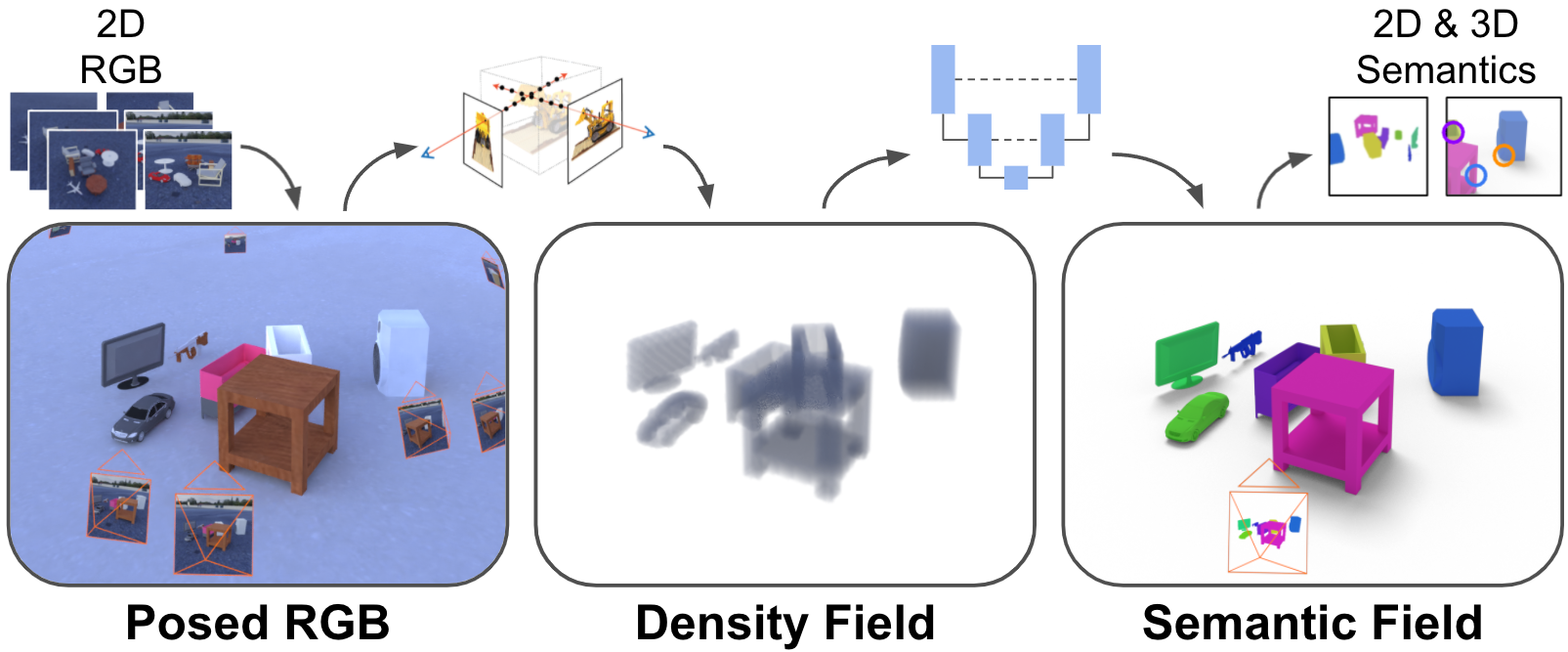
We present NeSF, a method for producing 3D semantic fields from posed RGB images alone. In place of classical 3D representations, our method builds on recent work in implicit neural scene representations wherein 3D structure is captured by point-wise functions. We leverage this methodology to recover 3D density fields upon which we then train a 3D semantic segmentation model supervised by posed 2D semantic maps. Despite being trained on 2D signals alone, our method is able to generate 3D-consistent semantic maps from novel camera poses and can be queried at arbitrary 3D points. Notably, NeSF is compatible with any method producing a density field, and its accuracy improves as the quality of the density field improves. Our empirical analysis demonstrates comparable quality to competitive 2D and 3D semantic segmentation baselines on complex, realistically-rendered synthetic scenes. Our method is the first to offer truly dense 3D scene segmentations requiring only 2D supervision for training, and does not require any semantic input for inference on novel scenes.